Loop every 1 minute for 7 hours, provide a date stamp, listen for syslog traffic with TCPDUMP, put the output to screen. This was to have a check running in a Putty screen so I could keep a manual check on syslog not feeding my appliance.
#!/bin/bash
COUNTER=0
while [ $COUNTER -lt 421 ]; do
date
tcpdump -i eth0 port 514 -c 3
let COUNTER=COUNTER+1
sleep 58
clear
sleep 1
done
.
Wednesday, December 28, 2011
Sunday, December 11, 2011
Breakdown of C Format Parameters: article 201106
Study notes from Hacking: The Art of Exploitation and C Programming in Easy Steps. This is a table of format parameters in the C programming language

.
.
Sunday, December 4, 2011
Notes on Memory Segmentation: article 201105
Notes taken from "Hacking: The Art of Exploitation, 2nd ed." Author Jon Erickson; Publisher No Starch Press.
Take aways: Compiled programs on x86 systems memory is divided into 5 segements each with specific purposes. The segments are: text, data, bss, heap, and stack.
Fortunately my career is also my hobby; information security. Forgiving all of the tired cliches, it is true; to really understand "your enemy" you must learn how they work. It is also my opinion that to protect information you must too learn how the systems it resides on, and through, work as well.
In my free time I have been educating myself on Assembly, C, Python, application security, and malware analysis. I have been at it for over a year now and due to the slow pace and lack of daily application of my studies I find myself having to re-review some mateirials as I progress. My current focus is the fantastic book "Hacking: The Art of Explotation". It is a great step through of showing the reader what C programming is, how to attack a poorly written program, and finally how to attack a network.
I decided to write some notes from my readings out here to provide myself with a reference and hopefully help provide information and understanding to others.
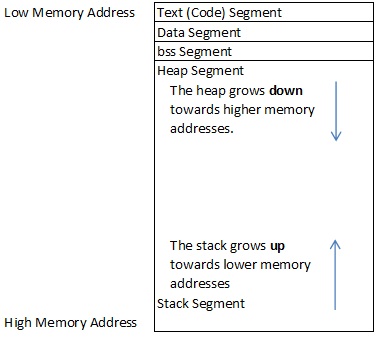
A compiled program's memory is divided into 5 segments: text, data, bss, heap and stack. Of course each segment has their own purpose.
TEXT SEGMENT:
Sometimes called the code segment. This location holds the assembled machine language instructions of the program. WRITE permissions are disabled in the TEXT segment. The segment is not used to store any variables, only code. The TEXT segment has a fixed size.
DATA SEGMENT:
Houses initialized global and static variables. This segment is writable but does have a fixed size.
BSS SEGMENT:
Houses uninitialized variables. This segment is writable but it too has a fixed size.
HEAP SEGMENT:
A segment of memory programmers can directly control. Blocks of memory in this segment can be allocated and used by the programmer. This segment's size can grow larger and smaller as needed. The HEAP memory grows DOWN towards HIGHER memory addresses.
STACK SEGMENT:
This segment is also writeable and is used as a "scratch pad" to store local function variables and context during function calls. The segment's size also can grow larger and smaller as needed. As the STACK segment expands it grows UP towards LOWER memory addresses.

.
Take aways: Compiled programs on x86 systems memory is divided into 5 segements each with specific purposes. The segments are: text, data, bss, heap, and stack.
Fortunately my career is also my hobby; information security. Forgiving all of the tired cliches, it is true; to really understand "your enemy" you must learn how they work. It is also my opinion that to protect information you must too learn how the systems it resides on, and through, work as well.
In my free time I have been educating myself on Assembly, C, Python, application security, and malware analysis. I have been at it for over a year now and due to the slow pace and lack of daily application of my studies I find myself having to re-review some mateirials as I progress. My current focus is the fantastic book "Hacking: The Art of Explotation". It is a great step through of showing the reader what C programming is, how to attack a poorly written program, and finally how to attack a network.
I decided to write some notes from my readings out here to provide myself with a reference and hopefully help provide information and understanding to others.
NOTES ON MEMORY SEGMENTATION
A compiled program's memory is divided into 5 segments: text, data, bss, heap and stack. Of course each segment has their own purpose.
TEXT SEGMENT:
Sometimes called the code segment. This location holds the assembled machine language instructions of the program. WRITE permissions are disabled in the TEXT segment. The segment is not used to store any variables, only code. The TEXT segment has a fixed size.
DATA SEGMENT:
Houses initialized global and static variables. This segment is writable but does have a fixed size.
BSS SEGMENT:
Houses uninitialized variables. This segment is writable but it too has a fixed size.
HEAP SEGMENT:
A segment of memory programmers can directly control. Blocks of memory in this segment can be allocated and used by the programmer. This segment's size can grow larger and smaller as needed. The HEAP memory grows DOWN towards HIGHER memory addresses.
STACK SEGMENT:
This segment is also writeable and is used as a "scratch pad" to store local function variables and context during function calls. The segment's size also can grow larger and smaller as needed. As the STACK segment expands it grows UP towards LOWER memory addresses.
.
Tuesday, June 28, 2011
Incident Repsonse; When To Call the Posse: article 201104
A security incident as defined in NIST SP800-61 rev 1 is a violation or imminent threat of violation of computer security policies, acceptable use policies, or standard security practices. That being the case then triggered web filters, IDS/IPS alerts, AV alerts, failed login attempts etc all combined can easily add up to hundreds if not thousands, possibly millions of "incidents" a day within an organization.
Thinking that any and all incidents require implementation of an organization's Incident Response Team is impractical. So when does one call in the posse? Unfortunately the answer is not black and white because it varies from organization to organization. However below are what I believe to be very good guidelines on when to make that call.
I asked Lenny Zelster via twitter if he had an answer and he was kind enough to provide very good info on his blog. By the time Lenny Zelster posted I had already performed further research on my own and fell upon one of the same sources as he did, NIST SP800-61. I will be using it as reference below; but I want to expound a little further on what NIST provided as well what US-CERT.gov and CERT.org have to say.
Down to it. It is up to an organization to determine the best use of their resources and with that determine when an incident warrants implementing a formal incident response. In the private sector one may be thinking more in the terms of what QUANTIFIES ($$$$) a formal incident response over what QUALIFIES as needing a formal incident response; and that is fine as this may very well be step one in the categorization process.
Even a government entity understands that priorities must be set on when to call in the posse. NIST itself suggests that minor incidents should be handled by basic staff instead of a formal response team.
I am a fan of ratings and categories because they provide fairly firm boundaries. I say firm because in the real world there is much gray. Ratings and categories help one determine what is not so important, what is important, and what is very freaking important!
First categories to create are IMPACT or EFFECT ratings. Many groups I have worked with in the past use Low Medium High. NIST breaks it down a bit more as shown in the table below taken from their SP800-61 guide page 3-15.
Once EFFECT ratings have been established an organization should assign CRITICALITY ratings which are typically based on system or processes affected. For example if malware hits one system, is not spreading, and has been quarantined by the AV program this may not warrant a formal incident response, if it is on a user's workstation; however, if it is on a payroll server then formalizing incident response may very well be implemented. This NIST pub provides another nice table as an example on page 3-16.
NIST goes even further and utilizes the values it provides to determine an overall severity score
The rating can then be compared to an incident impact rating chart also found on page 3-16
So based on the final score one will hopefully have the an idea of whether or not to call in the posse!
This does not directly pertain the implementation of the Incident Response Team but I think it does add even more value to the fact that not all incidents are equal and thus the need for incident prioritization. The Federal Incident Reporting Guidelines from US-Cert provides the table below for federal reporting time frames. Notice that some of incidents are reported on only a monthly basis.
So I hope this helps somebody out there get a grasp on incident response and prioritization, else as Lenny Zelster mentions in his blog "start panicking about every IDS or anti-virus alert, and you’ll not only develop hypertension, but will also waste the time of your staff."
Many thanks to Lenny Zelster, NIST, and CERT.
.
Thinking that any and all incidents require implementation of an organization's Incident Response Team is impractical. So when does one call in the posse? Unfortunately the answer is not black and white because it varies from organization to organization. However below are what I believe to be very good guidelines on when to make that call.
I asked Lenny Zelster via twitter if he had an answer and he was kind enough to provide very good info on his blog. By the time Lenny Zelster posted I had already performed further research on my own and fell upon one of the same sources as he did, NIST SP800-61. I will be using it as reference below; but I want to expound a little further on what NIST provided as well what US-CERT.gov and CERT.org have to say.
Down to it. It is up to an organization to determine the best use of their resources and with that determine when an incident warrants implementing a formal incident response. In the private sector one may be thinking more in the terms of what QUANTIFIES ($$$$) a formal incident response over what QUALIFIES as needing a formal incident response; and that is fine as this may very well be step one in the categorization process.
Looking at what the US Government Does
Even a government entity understands that priorities must be set on when to call in the posse. NIST itself suggests that minor incidents should be handled by basic staff instead of a formal response team.
I am a fan of ratings and categories because they provide fairly firm boundaries. I say firm because in the real world there is much gray. Ratings and categories help one determine what is not so important, what is important, and what is very freaking important!
First categories to create are IMPACT or EFFECT ratings. Many groups I have worked with in the past use Low Medium High. NIST breaks it down a bit more as shown in the table below taken from their SP800-61 guide page 3-15.

Once EFFECT ratings have been established an organization should assign CRITICALITY ratings which are typically based on system or processes affected. For example if malware hits one system, is not spreading, and has been quarantined by the AV program this may not warrant a formal incident response, if it is on a user's workstation; however, if it is on a payroll server then formalizing incident response may very well be implemented. This NIST pub provides another nice table as an example on page 3-16.

NIST goes even further and utilizes the values it provides to determine an overall severity score
Overall Severity/Effect Score = Round ((Current Effect Rating * 2.5) + (Projected Effect Rating * 2.5) + (System Criticality Rating * 5))
The rating can then be compared to an incident impact rating chart also found on page 3-16

So based on the final score one will hopefully have the an idea of whether or not to call in the posse!
A little more from the US Government:
This does not directly pertain the implementation of the Incident Response Team but I think it does add even more value to the fact that not all incidents are equal and thus the need for incident prioritization. The Federal Incident Reporting Guidelines from US-Cert provides the table below for federal reporting time frames. Notice that some of incidents are reported on only a monthly basis.

So I hope this helps somebody out there get a grasp on incident response and prioritization, else as Lenny Zelster mentions in his blog "start panicking about every IDS or anti-virus alert, and you’ll not only develop hypertension, but will also waste the time of your staff."
Many thanks to Lenny Zelster, NIST, and CERT.
.
Sunday, May 8, 2011
Honeynet Forensics Challenge 7 winner: article 201103
I am excited and honored to have tied for third place. Many thanks to Honeynet for offering these challenges!
Forensic Challenge 7 – “Forensic Analysis of a Compromised System” - And the winners are...
Sat, 05/07/2011 - 15:09 — angelo.dellaera
Folks, Guillame and Hugo have judged all submissions and results have been posted on the challenge web site. The winners are:
1. Dev Anand
2. Fernando Quintero & Camilo Zapata
3. (3 submissions) Matt Erasmus, Joseph Kahlich and Kevin Mau
Congratulations to the winners!
With challenge 7 completed, we are getting ready to launch challenge 8 on May 9th. This challenge has been prepared by Guido Landi and Angelo Dell'Aera from the Sysenter Chapter and it deals with
malware reverse engineering. We hope to see you participating!
Angelo Dell'Aera
The Honeynet Project
Original post found at: http://www.honeynet.org/node/667 .
Forensic Challenge 7 – “Forensic Analysis of a Compromised System” - And the winners are...
Sat, 05/07/2011 - 15:09 — angelo.dellaera
Folks, Guillame and Hugo have judged all submissions and results have been posted on the challenge web site. The winners are:
1. Dev Anand
2. Fernando Quintero & Camilo Zapata
3. (3 submissions) Matt Erasmus, Joseph Kahlich and Kevin Mau
Congratulations to the winners!
With challenge 7 completed, we are getting ready to launch challenge 8 on May 9th. This challenge has been prepared by Guido Landi and Angelo Dell'Aera from the Sysenter Chapter and it deals with
malware reverse engineering. We hope to see you participating!
Angelo Dell'Aera
The Honeynet Project
Original post found at: http://www.honeynet.org/node/667 .
Tuesday, April 12, 2011
PCRE CHEAT SHEET: article 201102
Takeaways: Perl Compatible Regular Expression Cheat Sheet
This is straight from the horses mouth: http://www.pcre.org/pcre.txt. The information below is a copy and paste from of the PCRESYNTAX (3) section. As it mentions below this a quick reference for syntax to perform matching. A deep description of the below can be found at the same link in the PCREPATTERN (3).
This comes in handy for me when working to understand or write Snort/Sourcefire rules; among other great uses such as analyzing or parsing log files.
PCRESYNTAX(3)
NAME
PCRE - Perl-compatible regular expressions
PCRE REGULAR EXPRESSION SYNTAX SUMMARY
The full syntax and semantics of the regular expressions that are sup-
ported by PCRE are described in the pcrepattern documentation. This
document contains just a quick-reference summary of the syntax.
QUOTING
\x where x is non-alphanumeric is a literal x
\Q...\E treat enclosed characters as literal
CHARACTERS
\a alarm, that is, the BEL character (hex 07)
\cx "control-x", where x is any ASCII character
\e escape (hex 1B)
\f formfeed (hex 0C)
\n newline (hex 0A)
\r carriage return (hex 0D)
\t tab (hex 09)
\ddd character with octal code ddd, or backreference
\xhh character with hex code hh
\x{hhh..} character with hex code hhh..
CHARACTER TYPES
. any character except newline;
in dotall mode, any character whatsoever
\C one byte, even in UTF-8 mode (best avoided)
\d a decimal digit
\D a character that is not a decimal digit
\h a horizontal whitespace character
\H a character that is not a horizontal whitespace character
\N a character that is not a newline
\p{xx} a character with the xx property
\P{xx} a character without the xx property
\R a newline sequence
\s a whitespace character
\S a character that is not a whitespace character
\v a vertical whitespace character
\V a character that is not a vertical whitespace character
\w a "word" character
\W a "non-word" character
\X an extended Unicode sequence
In PCRE, by default, \d, \D, \s, \S, \w, and \W recognize only ASCII
characters, even in UTF-8 mode. However, this can be changed by setting
the PCRE_UCP option.
GENERAL CATEGORY PROPERTIES FOR \p and \P
C Other
Cc Control
Cf Format
Cn Unassigned
Co Private use
Cs Surrogate
L Letter
Ll Lower case letter
Lm Modifier letter
Lo Other letter
Lt Title case letter
Lu Upper case letter
L& Ll, Lu, or Lt
M Mark
Mc Spacing mark
Me Enclosing mark
Mn Non-spacing mark
N Number
Nd Decimal number
Nl Letter number
No Other number
P Punctuation
Pc Connector punctuation
Pd Dash punctuation
Pe Close punctuation
Pf Final punctuation
Pi Initial punctuation
Po Other punctuation
Ps Open punctuation
S Symbol
Sc Currency symbol
Sk Modifier symbol
Sm Mathematical symbol
So Other symbol
Z Separator
Zl Line separator
Zp Paragraph separator
Zs Space separator
PCRE SPECIAL CATEGORY PROPERTIES FOR \p and \P
Xan Alphanumeric: union of properties L and N
Xps POSIX space: property Z or tab, NL, VT, FF, CR
Xsp Perl space: property Z or tab, NL, FF, CR
Xwd Perl word: property Xan or underscore
SCRIPT NAMES FOR \p AND \P
Arabic, Armenian, Avestan, Balinese, Bamum, Bengali, Bopomofo, Braille,
Buginese, Buhid, Canadian_Aboriginal, Carian, Cham, Cherokee, Common,
Coptic, Cuneiform, Cypriot, Cyrillic, Deseret, Devanagari, Egyp-
tian_Hieroglyphs, Ethiopic, Georgian, Glagolitic, Gothic, Greek,
Gujarati, Gurmukhi, Han, Hangul, Hanunoo, Hebrew, Hiragana, Impe-
rial_Aramaic, Inherited, Inscriptional_Pahlavi, Inscriptional_Parthian,
Javanese, Kaithi, Kannada, Katakana, Kayah_Li, Kharoshthi, Khmer, Lao,
Latin, Lepcha, Limbu, Linear_B, Lisu, Lycian, Lydian, Malayalam,
Meetei_Mayek, Mongolian, Myanmar, New_Tai_Lue, Nko, Ogham, Old_Italic,
Old_Persian, Old_South_Arabian, Old_Turkic, Ol_Chiki, Oriya, Osmanya,
Phags_Pa, Phoenician, Rejang, Runic, Samaritan, Saurashtra, Shavian,
Sinhala, Sundanese, Syloti_Nagri, Syriac, Tagalog, Tagbanwa, Tai_Le,
Tai_Tham, Tai_Viet, Tamil, Telugu, Thaana, Thai, Tibetan, Tifinagh,
Ugaritic, Vai, Yi.
CHARACTER CLASSES
[...] positive character class
[^...] negative character class
[x-y] range (can be used for hex characters)
[[:xxx:]] positive POSIX named set
[[:^xxx:]] negative POSIX named set
alnum alphanumeric
alpha alphabetic
ascii 0-127
blank space or tab
cntrl control character
digit decimal digit
graph printing, excluding space
lower lower case letter
print printing, including space
punct printing, excluding alphanumeric
space whitespace
upper upper case letter
word same as \w
xdigit hexadecimal digit
In PCRE, POSIX character set names recognize only ASCII characters by
default, but some of them use Unicode properties if PCRE_UCP is set.
You can use \Q...\E inside a character class.
QUANTIFIERS
? 0 or 1, greedy
?+ 0 or 1, possessive
?? 0 or 1, lazy
* 0 or more, greedy
*+ 0 or more, possessive
*? 0 or more, lazy
+ 1 or more, greedy
++ 1 or more, possessive
+? 1 or more, lazy
{n} exactly n
{n,m} at least n, no more than m, greedy
{n,m}+ at least n, no more than m, possessive
{n,m}? at least n, no more than m, lazy
{n,} n or more, greedy
{n,}+ n or more, possessive
{n,}? n or more, lazy
ANCHORS AND SIMPLE ASSERTIONS
\b word boundary
\B not a word boundary
^ start of subject
also after internal newline in multiline mode
\A start of subject
$ end of subject
also before newline at end of subject
also before internal newline in multiline mode
\Z end of subject
also before newline at end of subject
\z end of subject
\G first matching position in subject
MATCH POINT RESET
\K reset start of match
ALTERNATION
expr|expr|expr...
CAPTURING
(...) capturing group
(?...) named capturing group (Perl)
(?'name'...) named capturing group (Perl)
(?P...) named capturing group (Python)
(?:...) non-capturing group
(?|...) non-capturing group; reset group numbers for
capturing groups in each alternative
ATOMIC GROUPS
(?>...) atomic, non-capturing group
COMMENT
(?#....) comment (not nestable)
OPTION SETTING
(?i) caseless
(?J) allow duplicate names
(?m) multiline
(?s) single line (dotall)
(?U) default ungreedy (lazy)
(?x) extended (ignore white space)
(?-...) unset option(s)
The following are recognized only at the start of a pattern or after
one of the newline-setting options with similar syntax:
(*NO_START_OPT) no start-match optimization (PCRE_NO_START_OPTIMIZE)
(*UTF8) set UTF-8 mode (PCRE_UTF8)
(*UCP) set PCRE_UCP (use Unicode properties for \d etc)
LOOKAHEAD AND LOOKBEHIND ASSERTIONS
(?=...) positive look ahead
(?!...) negative look ahead
(?<=...) positive look behind
(? reference by name (Perl)
\k'name' reference by name (Perl)
\g{name} reference by name (Perl)
\k{name} reference by name (.NET)
(?P=name) reference by name (Python)
SUBROUTINE REFERENCES (POSSIBLY RECURSIVE)
(?R) recurse whole pattern
(?n) call subpattern by absolute number
(?+n) call subpattern by relative number
(?-n) call subpattern by relative number
(?&name) call subpattern by name (Perl)
(?P>name) call subpattern by name (Python)
\g call subpattern by name (Oniguruma)
\g'name' call subpattern by name (Oniguruma)
\g call subpattern by absolute number (Oniguruma)
\g'n' call subpattern by absolute number (Oniguruma)
\g<+n> call subpattern by relative number (PCRE extension)
\g'+n' call subpattern by relative number (PCRE extension)
\g<-n> call subpattern by relative number (PCRE extension)
\g'-n' call subpattern by relative number (PCRE extension)
CONDITIONAL PATTERNS
(?(condition)yes-pattern)
(?(condition)yes-pattern|no-pattern)
(?(n)... absolute reference condition
(?(+n)... relative reference condition
(?(-n)... relative reference condition
(?()... named reference condition (Perl)
(?('name')... named reference condition (Perl)
(?(name)... named reference condition (PCRE)
(?(R)... overall recursion condition
(?(Rn)... specific group recursion condition
(?(R&name)... specific recursion condition
(?(DEFINE)... define subpattern for reference
(?(assert)... assertion condition
BACKTRACKING CONTROL
The following act immediately they are reached:
(*ACCEPT) force successful match
(*FAIL) force backtrack; synonym (*F)
The following act only when a subsequent match failure causes a back-
track to reach them. They all force a match failure, but they differ in
what happens afterwards. Those that advance the start-of-match point do
so only if the pattern is not anchored.
(*COMMIT) overall failure, no advance of starting point
(*PRUNE) advance to next starting character
(*SKIP) advance start to current matching position
(*THEN) local failure, backtrack to next alternation
NEWLINE CONVENTIONS
These are recognized only at the very start of the pattern or after a
(*BSR_...) or (*UTF8) or (*UCP) option.
(*CR) carriage return only
(*LF) linefeed only
(*CRLF) carriage return followed by linefeed
(*ANYCRLF) all three of the above
(*ANY) any Unicode newline sequence
WHAT \R MATCHES
These are recognized only at the very start of the pattern or after a
(*...) option that sets the newline convention or UTF-8 or UCP mode.
(*BSR_ANYCRLF) CR, LF, or CRLF
(*BSR_UNICODE) any Unicode newline sequence
CALLOUTS
(?C) callout
(?Cn) callout with data n
SEE ALSO
pcrepattern(3), pcreapi(3), pcrecallout(3), pcrematching(3), pcre(3).
AUTHOR
Philip Hazel
University Computing Service
Cambridge CB2 3QH, England.
REVISION
Last updated: 21 November 2010
Copyright (c) 1997-2010 University of Cambridge.
This is straight from the horses mouth: http://www.pcre.org/pcre.txt. The information below is a copy and paste from of the PCRESYNTAX (3) section. As it mentions below this a quick reference for syntax to perform matching. A deep description of the below can be found at the same link in the PCREPATTERN (3).
This comes in handy for me when working to understand or write Snort/Sourcefire rules; among other great uses such as analyzing or parsing log files.
PCRESYNTAX(3)
NAME
PCRE - Perl-compatible regular expressions
PCRE REGULAR EXPRESSION SYNTAX SUMMARY
The full syntax and semantics of the regular expressions that are sup-
ported by PCRE are described in the pcrepattern documentation. This
document contains just a quick-reference summary of the syntax.
QUOTING
\x where x is non-alphanumeric is a literal x
\Q...\E treat enclosed characters as literal
CHARACTERS
\a alarm, that is, the BEL character (hex 07)
\cx "control-x", where x is any ASCII character
\e escape (hex 1B)
\f formfeed (hex 0C)
\n newline (hex 0A)
\r carriage return (hex 0D)
\t tab (hex 09)
\ddd character with octal code ddd, or backreference
\xhh character with hex code hh
\x{hhh..} character with hex code hhh..
CHARACTER TYPES
. any character except newline;
in dotall mode, any character whatsoever
\C one byte, even in UTF-8 mode (best avoided)
\d a decimal digit
\D a character that is not a decimal digit
\h a horizontal whitespace character
\H a character that is not a horizontal whitespace character
\N a character that is not a newline
\p{xx} a character with the xx property
\P{xx} a character without the xx property
\R a newline sequence
\s a whitespace character
\S a character that is not a whitespace character
\v a vertical whitespace character
\V a character that is not a vertical whitespace character
\w a "word" character
\W a "non-word" character
\X an extended Unicode sequence
In PCRE, by default, \d, \D, \s, \S, \w, and \W recognize only ASCII
characters, even in UTF-8 mode. However, this can be changed by setting
the PCRE_UCP option.
GENERAL CATEGORY PROPERTIES FOR \p and \P
C Other
Cc Control
Cf Format
Cn Unassigned
Co Private use
Cs Surrogate
L Letter
Ll Lower case letter
Lm Modifier letter
Lo Other letter
Lt Title case letter
Lu Upper case letter
L& Ll, Lu, or Lt
M Mark
Mc Spacing mark
Me Enclosing mark
Mn Non-spacing mark
N Number
Nd Decimal number
Nl Letter number
No Other number
P Punctuation
Pc Connector punctuation
Pd Dash punctuation
Pe Close punctuation
Pf Final punctuation
Pi Initial punctuation
Po Other punctuation
Ps Open punctuation
S Symbol
Sc Currency symbol
Sk Modifier symbol
Sm Mathematical symbol
So Other symbol
Z Separator
Zl Line separator
Zp Paragraph separator
Zs Space separator
PCRE SPECIAL CATEGORY PROPERTIES FOR \p and \P
Xan Alphanumeric: union of properties L and N
Xps POSIX space: property Z or tab, NL, VT, FF, CR
Xsp Perl space: property Z or tab, NL, FF, CR
Xwd Perl word: property Xan or underscore
SCRIPT NAMES FOR \p AND \P
Arabic, Armenian, Avestan, Balinese, Bamum, Bengali, Bopomofo, Braille,
Buginese, Buhid, Canadian_Aboriginal, Carian, Cham, Cherokee, Common,
Coptic, Cuneiform, Cypriot, Cyrillic, Deseret, Devanagari, Egyp-
tian_Hieroglyphs, Ethiopic, Georgian, Glagolitic, Gothic, Greek,
Gujarati, Gurmukhi, Han, Hangul, Hanunoo, Hebrew, Hiragana, Impe-
rial_Aramaic, Inherited, Inscriptional_Pahlavi, Inscriptional_Parthian,
Javanese, Kaithi, Kannada, Katakana, Kayah_Li, Kharoshthi, Khmer, Lao,
Latin, Lepcha, Limbu, Linear_B, Lisu, Lycian, Lydian, Malayalam,
Meetei_Mayek, Mongolian, Myanmar, New_Tai_Lue, Nko, Ogham, Old_Italic,
Old_Persian, Old_South_Arabian, Old_Turkic, Ol_Chiki, Oriya, Osmanya,
Phags_Pa, Phoenician, Rejang, Runic, Samaritan, Saurashtra, Shavian,
Sinhala, Sundanese, Syloti_Nagri, Syriac, Tagalog, Tagbanwa, Tai_Le,
Tai_Tham, Tai_Viet, Tamil, Telugu, Thaana, Thai, Tibetan, Tifinagh,
Ugaritic, Vai, Yi.
CHARACTER CLASSES
[...] positive character class
[^...] negative character class
[x-y] range (can be used for hex characters)
[[:xxx:]] positive POSIX named set
[[:^xxx:]] negative POSIX named set
alnum alphanumeric
alpha alphabetic
ascii 0-127
blank space or tab
cntrl control character
digit decimal digit
graph printing, excluding space
lower lower case letter
print printing, including space
punct printing, excluding alphanumeric
space whitespace
upper upper case letter
word same as \w
xdigit hexadecimal digit
In PCRE, POSIX character set names recognize only ASCII characters by
default, but some of them use Unicode properties if PCRE_UCP is set.
You can use \Q...\E inside a character class.
QUANTIFIERS
? 0 or 1, greedy
?+ 0 or 1, possessive
?? 0 or 1, lazy
* 0 or more, greedy
*+ 0 or more, possessive
*? 0 or more, lazy
+ 1 or more, greedy
++ 1 or more, possessive
+? 1 or more, lazy
{n} exactly n
{n,m} at least n, no more than m, greedy
{n,m}+ at least n, no more than m, possessive
{n,m}? at least n, no more than m, lazy
{n,} n or more, greedy
{n,}+ n or more, possessive
{n,}? n or more, lazy
ANCHORS AND SIMPLE ASSERTIONS
\b word boundary
\B not a word boundary
^ start of subject
also after internal newline in multiline mode
\A start of subject
$ end of subject
also before newline at end of subject
also before internal newline in multiline mode
\Z end of subject
also before newline at end of subject
\z end of subject
\G first matching position in subject
MATCH POINT RESET
\K reset start of match
ALTERNATION
expr|expr|expr...
CAPTURING
(...) capturing group
(?...) named capturing group (Perl)
(?'name'...) named capturing group (Perl)
(?P...) named capturing group (Python)
(?:...) non-capturing group
(?|...) non-capturing group; reset group numbers for
capturing groups in each alternative
ATOMIC GROUPS
(?>...) atomic, non-capturing group
COMMENT
(?#....) comment (not nestable)
OPTION SETTING
(?i) caseless
(?J) allow duplicate names
(?m) multiline
(?s) single line (dotall)
(?U) default ungreedy (lazy)
(?x) extended (ignore white space)
(?-...) unset option(s)
The following are recognized only at the start of a pattern or after
one of the newline-setting options with similar syntax:
(*NO_START_OPT) no start-match optimization (PCRE_NO_START_OPTIMIZE)
(*UTF8) set UTF-8 mode (PCRE_UTF8)
(*UCP) set PCRE_UCP (use Unicode properties for \d etc)
LOOKAHEAD AND LOOKBEHIND ASSERTIONS
(?=...) positive look ahead
(?!...) negative look ahead
(?<=...) positive look behind
(? reference by name (Perl)
\k'name' reference by name (Perl)
\g{name} reference by name (Perl)
\k{name} reference by name (.NET)
(?P=name) reference by name (Python)
SUBROUTINE REFERENCES (POSSIBLY RECURSIVE)
(?R) recurse whole pattern
(?n) call subpattern by absolute number
(?+n) call subpattern by relative number
(?-n) call subpattern by relative number
(?&name) call subpattern by name (Perl)
(?P>name) call subpattern by name (Python)
\g call subpattern by name (Oniguruma)
\g'name' call subpattern by name (Oniguruma)
\g call subpattern by absolute number (Oniguruma)
\g'n' call subpattern by absolute number (Oniguruma)
\g<+n> call subpattern by relative number (PCRE extension)
\g'+n' call subpattern by relative number (PCRE extension)
\g<-n> call subpattern by relative number (PCRE extension)
\g'-n' call subpattern by relative number (PCRE extension)
CONDITIONAL PATTERNS
(?(condition)yes-pattern)
(?(condition)yes-pattern|no-pattern)
(?(n)... absolute reference condition
(?(+n)... relative reference condition
(?(-n)... relative reference condition
(?()... named reference condition (Perl)
(?('name')... named reference condition (Perl)
(?(name)... named reference condition (PCRE)
(?(R)... overall recursion condition
(?(Rn)... specific group recursion condition
(?(R&name)... specific recursion condition
(?(DEFINE)... define subpattern for reference
(?(assert)... assertion condition
BACKTRACKING CONTROL
The following act immediately they are reached:
(*ACCEPT) force successful match
(*FAIL) force backtrack; synonym (*F)
The following act only when a subsequent match failure causes a back-
track to reach them. They all force a match failure, but they differ in
what happens afterwards. Those that advance the start-of-match point do
so only if the pattern is not anchored.
(*COMMIT) overall failure, no advance of starting point
(*PRUNE) advance to next starting character
(*SKIP) advance start to current matching position
(*THEN) local failure, backtrack to next alternation
NEWLINE CONVENTIONS
These are recognized only at the very start of the pattern or after a
(*BSR_...) or (*UTF8) or (*UCP) option.
(*CR) carriage return only
(*LF) linefeed only
(*CRLF) carriage return followed by linefeed
(*ANYCRLF) all three of the above
(*ANY) any Unicode newline sequence
WHAT \R MATCHES
These are recognized only at the very start of the pattern or after a
(*...) option that sets the newline convention or UTF-8 or UCP mode.
(*BSR_ANYCRLF) CR, LF, or CRLF
(*BSR_UNICODE) any Unicode newline sequence
CALLOUTS
(?C) callout
(?Cn) callout with data n
SEE ALSO
pcrepattern(3), pcreapi(3), pcrecallout(3), pcrematching(3), pcre(3).
AUTHOR
Philip Hazel
University Computing Service
Cambridge CB2 3QH, England.
REVISION
Last updated: 21 November 2010
Copyright (c) 1997-2010 University of Cambridge.
Sunday, January 16, 2011
Malicious Domain Check: article 201101
Takeaways: 3 websites to query to help determine if a site is or has possibly hosted malicious software: http://www.google.com/safebrowsing/diagnostic?site=whyjoseph.com, http://www.siteadvisor.com/ and http://www.malwaredomainlist.com/mdl.php
During the course of my duties I want to verify if a URL visited is indeed possibly malicious. You see I have a "trust but verify" philosophy when it comes to vendors and technology. This bit of doubt should not be taken as offensive as it merely stems from the fact that we are all human and we make mistakes. Beyond mistakes there is also the fact that technologies can be subverted; but I have digressed.
The point of this post is that I use 3 or more sources to help verify a security tool I use that reports that a domain is malicious.
Google Safe Browsing Project
http://www.google.com/safebrowsing/diagnostic?site=
Google's link gives good info for the past 90 days. It will report the last time it visited the site and if malicious pages are found it will give a count of those pages along with a short list of additional malicious sites if the primary is acting as a host. In case you don't know when using the the link above replace the part after the "=" sign, in this case, with the actual domain name. For example: http://www.google.com/safebrowsing/diagnostic?site=whyjoseph.com
McAfee Site Advisor
http://www.siteadvisor.com/
On this page you simply enter the name of the domain into a field on the web page. This site provides a green check or a red x based it's finding of the site. I did notice once that it actually showed what malicious software file would be downloaded if the malicious site were visited.
Malware Domain List (MDL)
http://www.malwaredomainlist.com/mdl.php
This site is the foundation a great community for malware analysis. But since we are just looking to determine if they have posted a site as possibly malicious you can query their database. The page has a field where you can enter the domain name or just use partial names to see if there is a match.
Well I hope this helps anybody that comes across this page and if there are any other sources or thoughts on this please comment!
.
During the course of my duties I want to verify if a URL visited is indeed possibly malicious. You see I have a "trust but verify" philosophy when it comes to vendors and technology. This bit of doubt should not be taken as offensive as it merely stems from the fact that we are all human and we make mistakes. Beyond mistakes there is also the fact that technologies can be subverted; but I have digressed.
The point of this post is that I use 3 or more sources to help verify a security tool I use that reports that a domain is malicious.
Google Safe Browsing Project
http://www.google.com/safebrowsing/diagnostic?site=
Google's link gives good info for the past 90 days. It will report the last time it visited the site and if malicious pages are found it will give a count of those pages along with a short list of additional malicious sites if the primary is acting as a host. In case you don't know when using the the link above replace the part after the "=" sign, in this case
McAfee Site Advisor
http://www.siteadvisor.com/
On this page you simply enter the name of the domain into a field on the web page. This site provides a green check or a red x based it's finding of the site. I did notice once that it actually showed what malicious software file would be downloaded if the malicious site were visited.
Malware Domain List (MDL)
http://www.malwaredomainlist.com/mdl.php
This site is the foundation a great community for malware analysis. But since we are just looking to determine if they have posted a site as possibly malicious you can query their database. The page has a field where you can enter the domain name or just use partial names to see if there is a match.
Well I hope this helps anybody that comes across this page and if there are any other sources or thoughts on this please comment!
.
Subscribe to:
Posts (Atom)
